Les parseurs de contenus sont souvent intéressants car ils permettent de récupérer des informations sur les sites externes afin de les syndiquer et les afficher dans nos propres pages ou systèmes en ligne. Les réseaux sociaux sont devenus logiquement la cible des développeurs car nous cherchons parfois à récupérer nos publications (ou autres informations) à la volée pour les afficher sur nos sites web (c'est le cas sur mon site www.internet-formation.fr, je parse les publications de ma page pro Google+ par exemple). Notre cible sera Facebook aujourd'hui, et peut-être que je vous donnerai d'autres méthodes à l'avenir pour d'autres réseaux sociaux (si vous êtes sage !!! :D).
Vous pouvez télécharger le code du parseur dans le fichier suivant, en sachant que le style et l'affichage peuvent être totalement modifiés bien entendu (le rendu affiché ci-dessous correspond au code PHP fourni et à la capture finale de cet article).
Télécharger “Parseur Facebook”parser-facebook.zip – Téléchargé 24851 fois – 2,54 Ko
Comment parser avec PHP ?
Il existe plusieurs méthodes pour récupérer des contenus provenant d'autres sites. Toutes ont leurs avantages et inconvénients, et je dirais que c'est davantage nos habitudes qui nous font pencher pour une technique plutôt qu'une autre. En voici une courte liste :
- récupérer des flux RSS (ou Atom) et les informations qu'il contient grâce à JSON ou simpleXML ;
- récupérer des informations avec cURL ou file_get_contents() en PHP (ou autre langage) puis traiter les contenus ;
- mélanger ces deux types de techniques.
Nous allons mélanger les deux méthodes dans notre cas pour Facebook, mais sachez qu'un parseur avec simpleXML pourrait suffire au fond, bien que ce soit peut-être moins efficace à la longue.
Quelles données dans les flux RSS de Facebook ?
Facebook ne fournit pas beaucoup d'informations dans ses flux RSS ou Atom des pages professionnelles, nous devons donc nous contenter du minimum, que ce soit en termes de contenus mais aussi du point de vue technique. Par exemple, les publications n'ont pas de titre à proprement parler, il s'agit uniquement du début des publications, donc parfois, le doublon est gênant voir perturbant quand nous voulons parser proprement.
Nous allons récupérer les données suivantes grâce à l'ID de la page (ou du compte) de l'utilisateur :
- titre généré de publication ;
- date de publication ;
- auteur de la publication (toujours le même dans le cas d'une page unique) ;
- contenu des posts.
Pour rappel, il suffit de vous rendre dans une page professionnelle puis de cliquer sur "Paramètres", "Informations sur la page" puis "Identifiant de page Facebook" pour récupérer l'ID qui nous sera utile pour faire fonctionner le parseur (voir illustration ci-dessous).

Parser en PHP sur Facebook avec cURL et simpleXML
La base du parseur PHP est fondée sur l'URL des flux de Facebook, qui ressemble à ceci : https://www.facebook.com/feeds/page.php?id=xxxxxxxxxxxxx&format=rss20 (les formats tolérés sont "json", "atom10" et "rss20", c'est ce dernier qui nous intéresse ici !).
Pour faire fonctionner le système, cURL nous permet de lire le flux RSS ou Atom et de récupérer les contenus avec la méthode que nous préférons, que ce soit simpleXML ou JSON. J'ai opté pour simpleXML ici mais j'aurais très bien pu obtenir un résultat équivalent avec JSON.
L'avantage de cURL est de permettre d'une part d'opter pour l'un ou l'autre des deux systèmes mais aussi d'ajouter plusieurs options de crawl non négligeables afin d'être "discret" auprès de Facebook. Par exemple, nous pouvons passer par un proxy, cacher notre URL referer, suivre les redirections, ajouter des entêtes... Au final, ces quelques atouts permettent d'être plus transparents auprès de Facebook, c'est pourquoi j'ai choisi cette technique, bien qu'elle rajoute quelques lignes de code.
Sans plus attendre, passons au code et entrons dans le vif du sujet. La fonction parserFacebook() prend trois paramètres :
- ID de la page Facebook.
- Nombre de publications à afficher (de 1 à 25 normalement mais souvent de 1 à 10 maximum), fixé à 5 par défaut.
- Affichage des illustrations (true) ou non (false) dans les publications, fixé sur "false" par défaut. Ainsi, nous pouvons afficher uniquement les textes et les liens ou choisir d'afficher les contenus complets tels qu'affichés dans les flux RSS et Atom de Facebook.
Voici la fonction PHP complète avec cURL et simpleXML :
function parserFacebook($idPage = '', $nb = 5, $keepImg = false) {
// URL de Facebook
$url = "https://www.facebook.com/feeds/page.php?id=";
$url.= $idPage;
$url.= "&format=rss20"; // ou "json" ou "atom10"
// Lancement de cURL
$curl = curl_init($url);
// Ajout d'entêtes pour se faire passer pour un robot
$header = array(
"Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5",
"Cache-Control: max-age=0",
"Accept-Charset: UTF-8;q=0.7,*;q=0.7",
"Pragma: " // Pas de cache par défaut
);
// User-agent automatique (au pire, en choisir un précis)
$ua = $_SERVER['HTTP_USER_AGENT'];
// URL referer à renvoyer à Facebook (vide recommandé !)
$referer = "";
// Timeout de cURL
$timeout = 30;
// Options de cURL
curl_setopt($curl, CURLOPT_USERAGENT, $ua);
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
curl_setopt($curl, CURLOPT_REFERER, $referer);
curl_setopt($curl, CURLOPT_AUTOREFERER, true);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($curl, CURLOPT_CONNECTTIMEOUT, $timeout);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, false);
// Exécution de cURL
$cURLxml = curl_exec($curl);
// Fermeture de cURL
curl_close($curl);
// Récupération des données XML avec simpleXML
$simpleXML = simplexml_load_string($cURLxml);
$simpleXML = $simpleXML->channel->item;
// Conservation uniquement des posts réels
foreach($simpleXML as $item) {
$verif = preg_match("#(/posts/|/photos/|permalink)#iU", $item->link);
if($verif == true) {
$tabItem[] = $item;
}
}
// Instanciation des variables par défaut
$resultat = '';
$i = 0;
// Boucle de récupération des résultats
foreach($tabItem as $item) {
// Instanciation des variables
$urlPage= "https://www.facebook.com/".$idPage;
$date = date("d/m/Y à h:i:s", strtotime($item->pubDate));
$auteur = $item->author;
$lien = $item->link;
$titre = trim($item->title);
$texte = trim($item->description);
// Tant que le nombre de résultats correspond à nos souhaits
if($i < $nb) {
// Supprime les sauts de ligne inutiles
$regex = '#(<br(/?)>)+(<a(.*)>(.*)</a>)(<br(/?)>)?#iU';
$texte = preg_replace($regex, '$3', $texte);
$regex = '#(<br(/?)>){2,}#iU';
$texte = preg_replace($regex, '<br/>', $texte);
// On supprime les images si on ne veut garder que le texte
if($keepImg == false) {
$regex = '#(<a(.*)><img(.*)></a>)#iU';
$texte = preg_replace($regex, '', $texte);
} else {
$regex = '#(<a(.*)><img(.*)></a>)#iU';
$texte = preg_replace($regex, '<p>$1<p>', $texte);
}
// Suppression du titre répété dans le texte...
$texte = str_ireplace($titre, '', $texte);
// Formatage du résultat
$resultat .= '<div class="block">';
$resultat .= '<h3 class="titre"><a href="'.$lien.'" target="_blank">'.$titre.'</a></h3>';
$resultat .= '<div class="meta">Publié le '.$date.' par <a href="'.$urlPage.'" target="_blank">'.$auteur.'</a></div>';
$resultat .= '<div class="contenu">'.$texte.'</div>';
$resultat .= '</div>';
} else {
break;
}
// Incrémentation
$i++;
}
// Retourne le résultat final
return $resultat;
}
?>
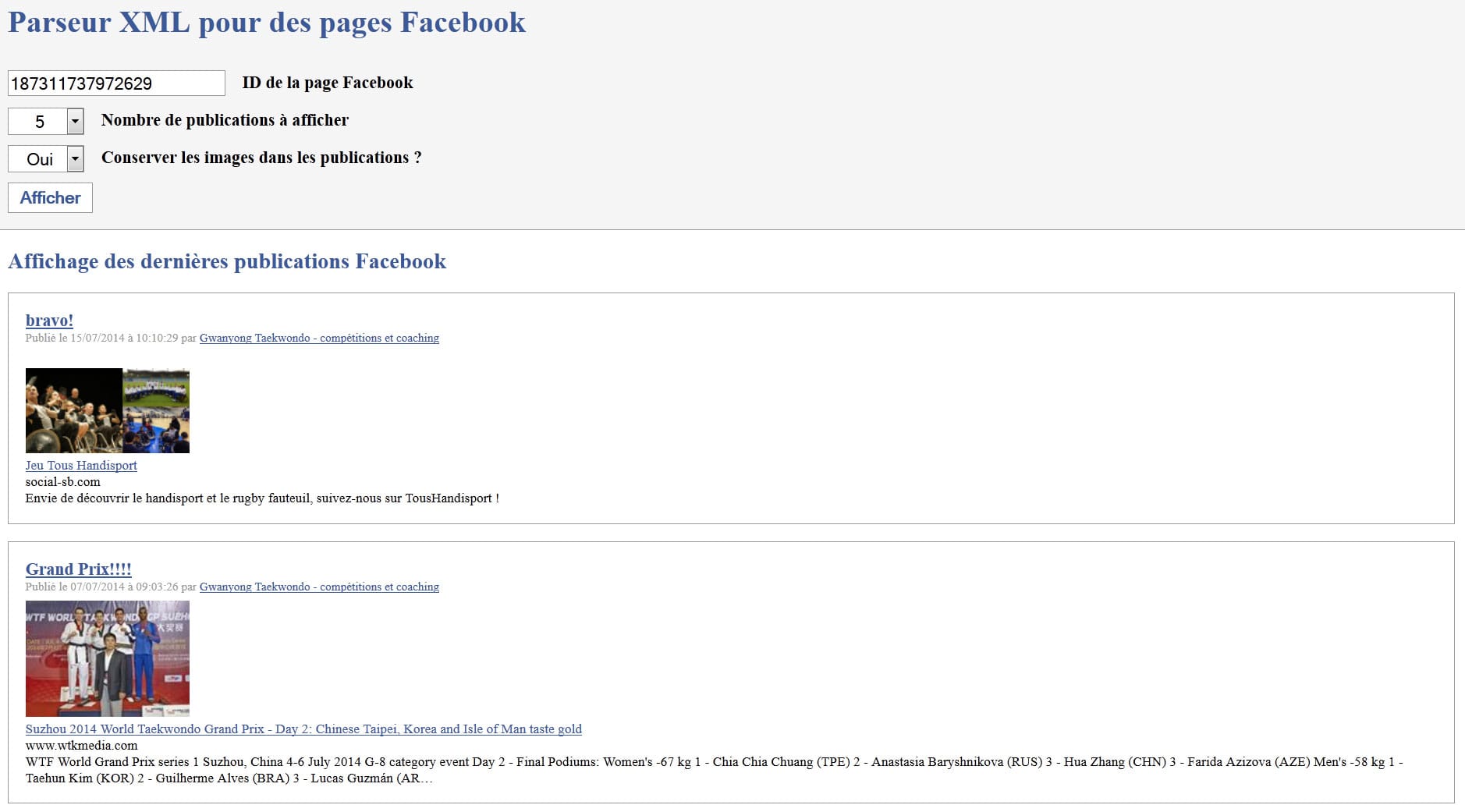
Si ce parseur PHP vous a plu, n'hésitez pas à m'en demander pour d'autres réseaux ou sous d'autres, cela pourra faire l'objet d'autres articles à l'avenir, il m'arrive parfois de manquer d'idée mais vous êtes ma source d'inspiration alors je jette cette bouteille à la mer... :D